Volume 4, Number 2—June 1998
Perspective
Accommodating Error Analysis in Comparison and Clustering of Molecular Fingerprints
Abstract
Molecular epidemiologic studies of infectious diseases rely on pathogen genotype comparisons, which usually yield patterns comprising sets of DNA fragments (DNA fingerprints). We use a highly developed genotyping system, IS6110-based restriction fragment length polymorphism analysis of Mycobacterium tuberculosis, to develop a computational method that automates comparison of large numbers of fingerprints. Because error in fragment length measurements is proportional to fragment length and is positively correlated for fragments within a lane, an align-and-count method that compensates for relative scaling of lanes reliably counts matching fragments between lanes. Results of a two-step method we developed to cluster identical fingerprints agree closely with 5 years of computer-assisted visual matching among 1,335 M. tuberculosis fingerprints. Fully documented and validated methods of automated comparison and clustering will greatly expand the scope of molecular epidemiology.
The combination of conventional epidemiologic investigations with molecular techniques for genotyping pathogens has elucidated the epidemiology of many infectious diseases. The most frequently used genotyping techniques (e.g., pulsed-field gel electrophoresis, restriction fragment length polymorphism [RFLP], and randomly amplified polymorphic DNA) yield fragment-based data. Fewer than 100 patterns can be compared visually. For larger numbers, commercially available computer programs can be used to identify a manageable subset of potentially matching patterns, which are then compared visually. This approach is accurate but cumbersome and excessively labor-intensive as the number of isolates exceeds several hundred. Furthermore, the results of computer-assisted matching are not as reproducible as systematic computational methods. These limitations significantly constrain the size, scope, and standardization of molecular epidemiologic investigations. We present an approach by which identical patterns can be identified from large collections of DNA fingerprints.
The number of IS6110 fingerprints continues to increase, with many studies across the globe producing IS6110 data to characterize Mycobacterium tuberculosis isolates. Such molecular epidemiologic studies provide information about tuberculosis (TB) transmission patterns. Studies in Ethiopia, Tunisia, and The Netherlands (1), South Africa (2), India (3), Denmark and Greenland (4,5), the United States (6), and Tanzania (7), among many others, exploit IS6110-based RFLP genetic fingerprints.
We developed an automated computational system, in which a statistical analysis of the error in measuring fragment sizes provides a conceptual framework for comparing sets of fragment lengths. The computational approach to lane comparison—align-and-count method (ACM)—permits calculation of the number of fragments that match between two IS6110-based RFLP fingerprints. The parameters of the computational ACM are adjusted to provide the same high sensitivity as the labor-intensive visual inspection used over the last 5 years.
We developed an approach to identifying a set of identical fingerprints when the identity of the fingerprints is nontransitive. We also explored improving the specificity among matched fingerprints to reveal additional information in RFLP lanes.
Genotyping M. tuberculosis isolates with IS6100-based RFLP fingerprinting was performed as described in van Embden et al., 1993 (8). Computer-assisted comparison and clustering were performed on the RFLP lanes as described in Woelffer et al., 1996 (9).
Internal standards were used to quantitate fragment sizes visualized with a DNA probe to IS6110. Two films' exposures were scanned into Whole Band Analyzer software (BioImage, Ann Arbor, MI, USA); one was obtained when probing for the internal standard, the other when probing for IS6110. The resulting images were aligned with three registration marks that gave reference to the original nylon membrane. The Whole Band Analyzer software quantitated fragment lengths for the IS6110-visualized bands, which were inspected and edited manually in the software package. The resulting collections of fragment lengths for each lane (bacterial isolate or laboratory strain H37Rv) were exported to our ACM software and compared with other lanes.
The following is a descriptive summary of the principles underlying the analysis (Appendix).
Analysis of Error in Data
The magnitude and characteristics of experimental error were empirically assessed by analyzing variation in the results obtained from a reference strain included in each experiment (gel). The absolute and proportional differences in the measured fragment lengths of biologically identical samples of this strain were calculated; results showed that the error in measurement was proportional to fragment length and greater between than within gels.
Align-and-Count Matching Algorithm
Figure 1
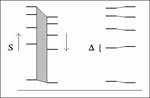
Figure 1. The align-and-count method finds the maximum number of mutually closest bands within a threshold deviation value ∆, for a search across a range S of scaling values. The two lanes are...
A method for matching was developed to accommodate the empirically defined error. The fragment length data from two lanes were scaled through a range of values, and the maximum number of mutually closest bands falling within a threshold tolerance was reported (Figure 1). The acceptable tolerance was smaller when lanes from the same gel were compared than when lanes from different gels were compared. An animated demonstration of this method is accessible on the Internet (URL for use with a graphics-capable Web browser: http://molepi.stanford.edu/hugh/acm/counting).
A Graph-Theoretic Approach to Identical Fingerprints
We considered pairs of patterns identical if all fragments matched. However, because the results might be nontransitive (A might be identical to B, B identical to C, but A not identical to C), the identification of groups of matched patterns is more complicated. A graph-theoretic approach was used to assemble clusters of matching fingerprints.
Alignment and Analysis of Residual Error
We further aligned collections of lanes determined to match according to the above algorithms. The optimal alignment was defined as that which minimized the proportional error between putatively identical fragments. This analytic step, which is comparable to the experimental approach of rerunning clustered strains in the same gel, improved the ability to distinguish similar, but nonidentical fingerprints.
Figure 3

Figure 3. Additional alignment of very similar patterns can identify clearly distinct patterns. Measurement noise obscures the detailed relationships between 26 patterns that were identified from 1,335 as being very similar. However, after...
Figure 2

Figure 2. Means and two standard errors of the mean error bars for pairwise comparisons among 116 12-banded H37Rv lanes show that error is consistently larger when comparing lanes between gels than when...
Investigating the absolute error for pairs of 116 H37Rv lanes (Figure 2), we found that the error was consistently higher in gel-to-gel comparisons than in comparisons of lanes from the same gel. Error was proportional to fragment length for the range of fragment lengths from 0.9 kbp up to at least 5 kbp (Figure 2), which included 90% of the bands in the fingerprint data from San Francisco. The latter empirical result was consistent with the fact that the distance migrated by a DNA fragment on an electrophoresis gel is typically proportional to the logarithm of the fragment length. Furthermore, the error found when we compared one band of a lane to that band in another lane was positively correlated to the error found for the other bands; in other words, if the first band in lane A was larger than the average measurement for that band, it was likely that the other bands in lane A would be larger than the average measurements. This positive correlation was intuitively evident in comparing lane maps (i.e., when comparing graphic representations of the fragment lengths). In Figure 3, the set of lane maps on the left are measurements of a genotype found in San Francisco. With the exception of the fourth lane from the right, they represent a set of identical patterns. Note that the error is mostly a scaling error and that if one fragment is larger than average for that lane, the others are very likely to be larger also. These two observations—that error is proportional to fragment length and positively correlated for bands within a given lane—suggests two classes of error: one is a property of each band; the second is a property of each lane. This analysis motivated us to develop a computational algorithm that scales fingerprints and measures the number of mutually closest bands within threshold sizes of each other for the best alignment, i.e., the scaling that maximizes the number of matching fragments.
By optimally aligning (i.e., minimizing the sum of proportional errors) pairs of H37Rv lanes, we find a distribution of scaling factors and of residual error. Table 1 shows 6,641 pairwise comparisons of 91 replicate lanes (members of each pair are taken from different gels). The mean value of s, the scaling factor, for these 6,641 alignments is 0.0212, and the standard deviation of s is 0.0189. The reduction in error due to alignment is approximately twofold, to approximately 1% with a standard deviation also of approximately 1% (Table 1); therefore, a search range, S, of 0.10 will allow for virtually every incidence of scaling error in the data. (Assuming normally distributed scaling and noting that 0.10 lies more than four standard deviations about the mean scaling error, we conclude that scaling error will not be compensated in fewer than 1 out of 10,000 independent pairwise comparisons.) Employing a deviation tolerance, ∆, of 0.045 should ensure a sensitivity very close to 100% for matching individual bands, after alignment. (Assuming normally distributed differences between replicate band measurements and a deviation tolerance of 4.5%, which is approximately 3.5 standard deviations above the mean fragment length error after alignment, one should falsely conclude two identical bands do not match with an approximate probability of 0.0002.) These parameter values, together with the number of incremental searches, I, set to 100, empirically gave results agreeing closely with visual inspection by experienced researchers who matched entire lanes. Similarly, one may use analysis of within gel lane error to determine the parameter values for the ACM to match lanes from the same gel.
Both the range of scaling factors and the threshold deviations are derived from empirical investigation of the San Francisco data. An adjustment for larger error in measurement is included for the more rare larger fragment length bands. In applying the ACM to San Francisco bacterial fingerprints, ∆ is allowed to increase at a rate of 0.005/kbp above a value of 7 kbp.
To evaluate the performance of the ACM, we analyzed (by computer-assisted visual inspection and by ACM) 125 lanes from bacterial isolates obtained in the first half of 1996. We evaluated ACM's performance by first determining whether a 1996 lane matched all bands to lanes in visually defined clusters (from previous years), matched other 1996 lanes, or did not find any identical matches at all. The automated matching of the 1996 lanes agreed nearly perfectly with the visual analysis; the few conflicting results were due to inconsistencies in the existing data (e.g., two bands of nearly identical size being edited sometimes as one band and sometimes as two). Humans often compensate for such inconsistencies, whereas a computational method would have to have such capabilities explicitly built in.
Using ACM, we analyzed all 890,445 pairwise comparisons of isolates from 1,335 TB cases in San Francisco from 1991 to mid-1996. The autoclusters defined from the pairwise comparisons agreed closely with the clusters defined by computer-assisted visual inspection (Table 2). An example of one autocluster is shown in Figure 3. Without additional alignment, noise in fragment length measurements makes it difficult to determine if these putative clusters include individual patterns which, although similar, are distinct (outliers) or if the cluster contains identifiable subgroups of patterns (subclusters).
We then further analyzed autoclusters and identified more precisely nonidentical genotypes. Refinement of clusters begins with defining a consensus pattern for the cluster (consisting of the collection of mean fragment lengths for each band). Then the fragment lengths for each putative member of the autocluster are aligned to the consensus pattern. After alignment, a pattern can be easily identified as an outlier (Figure 3).
Figure 4

Figure 4. Histograms of the fragment lengths for 84 two-banded patterns connected by identity (autoclustered with in-house software) exhibit enough spread in values to make detecting outliers and band shifts difficult (a,b). Aligning...
Figure 5
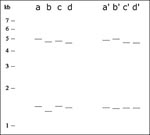
If the analysis of a refined, aligned cluster shows multiple outliers, realignment of subsets of lanes can be used to reveal subclusters of identical patterns. In Figure 4 the distributions of fragment lengths before (a,b) and after (c,d) an initial alignment are presented for an autocluster of 84 2-banders from San Francisco. Given that the aligned bands are clearly split into two distributions, we split the autocluster into two subclusters. A set of 26 fingerprints (group 1) is aligned to its assembled mean-value lane (Figure 4 e,f), as is a set of 58 fingerprints (group 2, Figure 4 g,h). The contrast between the original fragment length data and the two well-aligned groups of fingerprints shows that the higher fragment length band is shifted between the two groups and no clear outliers exist after alignment. Figure 5 shows that alignment greatly improves a difficult-to-resolve clustering issue among four lanes.
Preliminary investigation with a polymorphic GC-rich sequence (PGRS) fingerprinting method shows that the two subclusters exhibit distinct fingerprints, which further validates the increased specificity in IS6110 fingerprints. Of 81 PGRS genotyped autoclustered 2-banders, 63 fall into eight visually defined clusters, the remaining being unique PGRS patterns among the members of the IS6110 2-banded autocluster. Each cluster consists of isolates that all fall into one or the other IS6110-refined subcluster.
We have developed and validated a systematic approach to pairwise comparison and clustering of identical patterns in a large data set of DNA fragment-based genotypes. Incorporating a control pattern in each experiment allows the nature and magnitude of error in DNA fragment length measurements to be determined. An analysis of measurement error provides parameter values to use with algorithms that accommodate these errors. Relative scaling of entire lanes, an important characteristic of the error generated in quantitating fragment lengths from RFLP patterns used to type M. tuberculosis isolates, arises in part from aligning two images of a gel, one for internal lane size standards and one for data fragments; the image of internal standards and the image of data fragments are registered by three marks. Error in registration of the two images occurs, leading to the scaling effect in the fragment lengths reported. We strongly suggest that software for analyzing internal lane size standards and data fragments from separate images permit (and encourage) use of more than three registration marks. While internal standards compensate for idiosyncrasies in lane-specific fragment mobility, the limitations imposed by poor registration methods can result in increased scaling error. We have demonstrated that allowing for scaling, as in ACM, greatly assists in automating matching; incorporating alignment of pairs of lanes into the method has provided fully automated lane matching that agrees closely with results of the well-established method of computer-assisted visual comparison. We successfully address the nontransitivity of pairwise identity and once again use scaling of lanes to ensure the reliability of automated clustering of identical patterns.
Alignment of DNA fragment patterns removes noise in clusters of fingerprints, showing further specificity in genotyping. This is analogous to the experimental approach of rerunning similar patterns on a single gel to reduce intergel noise. Mathematical transformation of the fragment length data yields similar information for far less cost in labor and materials. Further automated clustering within sets of aligned patterns could exploit the fact that we assume putative homology of fragments. As the aligned patterns have the same number of fragments, the residual error presents a multidimensional clustering problem; each pattern may deviate from the mean-value pattern in any of the fragment lengths. This clustering may prove more straightforward than the more general problem of clustering among patterns differing in numbers of fragments.
Numerous commercial packages of computer software are available to compare and match DNA fragment patterns. The availability of these systems fosters unquestioning application of turnkey pattern matching and clustering methods, which are not always fully documented or validated (for fragment-based genotypes) in the scientific literature. While possibly acceptable for small studies when visually validated, this approach to data analysis is risky for large studies. The methods for matching DNA fragment patterns presented in this paper should be an adjunct to software packages that quantitate fragments. We provide a systematic approach to analysis of fragment length estimates, appropriate whether the numerical data are generated by hand using a ruler and arithmetic or are output by a multithousand dollar gel analyzer. This approach can thus be used by molecular epidemiologists working with both large and small budgets around the world. We anticipate that our methods can be incorporated into existing commercial software packages with broad distribution and encourage similar documentation in peer-reviewed journals of other methods provided in software packages.
In addition, our focus on the use of fragment length data, as opposed to the comparison of actual images, will foster comparison of data generated in different laboratories that use different proprietary software. We are working on a World-Wide Web–based system to facilitate IS6110 genotype data sharing.
The availability of a precise and validated method to count the number of matching fragments in a pairwise fashion among very large numbers of patterns now permits an assessment of the importance and usefulness of approaches that exploit fingerprint similarity. In conjunction with the growing understanding of the underlying biology of IS6110 instability and the relevant statistical issues, this may greatly expand the scope of TB molecular epidemiology.
A general question arises when comparing molecular fingerprints: how many bands need to match to indicate a close biologic relationship? Aside from the issues of defining biologic "closeness"—too often ignored in epidemiologic studies—technical issues are relevant to ACM. The usefulness of the matched band information output by ACM depends on at least several factors: the underlying band size distribution from which fingerprint bands are sampled, the independence of sampled bands, measurement error (both scaling and independent band error), the length of the gel, and the number of fragments. At one extreme, where error is large and few bands are observed, even in the case of a perfect match, statistical analysis may fail to reject coincidental band matches. By using computer simulation and sets of assumptions regarding band size distributions, one may learn about the role of coincidental band matching. We are actively researching these issues for IS6110 fingerprint comparisons. Furthermore, we intend to provide a general computational framework in which one may assess error in laboratory measurement, the appropriateness of ACM for analyzing data (and appropriate parameter values to use with the method), and the role of coincidence in band matching. Information regarding computer programs for various tasks, including ACM matching itself, will be made available on the Internet at http://molepi.stanford.edu/hugh/acm.
A study of M. tuberculosis isolates from northern Tanzania demonstrates the utility of partial matching (3). The study brings into focus difficulties inherent in employing one-parameter tolerance for DNA fragment-based genotype matching, a technical issue effectively addressed by ACM. Gillespie et al. (7) also call attention to the poor specificity of low copy number IS6110-based fingerprints, exacerbated by the use of the Dice coefficient. We are pursuing alternative similarity measures that use the numbers of matching fragments identified by ACM and are tailored to the needs of epidemiologic investigations. Dendogram clustering methods often provided in software targeted at DNA-fragment genotype management and analysis could in some instances fail to reconstruct the correct relationships among infectious organism isolates, even when presented perfect clock-like genetic distances. This may result in part from the fact that fast-evolving markers are characterized for isolates sampled over a period; samples are not contemporaneous. In conjunction with our efforts to define similarity measures, we are also working to modify phylogenetic inference tools used in clinical and molecular epidemiologic settings to better handle the data typically analyzed in molecular fingerprint management and analysis software.
Hugh Salamon is a postdoctoral researcher at Stanford University Medical Center; he is focusing on molecular epidemiology and Mycobacterium tuberculosis genomics. In his work as computer programmer in the Department of Medicine at the University of California, San Francisco, he writes custom software for many analyses and maintains a web site (http://molepi.stanford.edu) at Stanford University.
Acknowledgments
We thank Philip Hopewell, for his interest in and support for continued development of M. tuberculosis genetic fingerprinting in TB research; Mike Cummings, for his participation in numerous meetings regarding analysis of the fingerprint data, his input and discussions in the evolution of ideas leading to the work presented herein, and his comments on manuscripts; Melvin Javonillo, for help in accessing fingerprint data; Daniel Ruderman, for help with the issue of logarithmic alignment; and Marcel Behr and Sam Warren, for comments on manuscripts.
This research was supported by NIH grants AI35969, AI34238.
References
- Hermans PW, Messadi F, Guebrexabher H, van Soolingen D, de Haas PE, Heersma H, Analysis of the population structure of Mycobacterium tuberculosis in Ethiopia, Tunisia, and the Netherlands: usefulness of DNA typing for global tuberculosis epidemiology. J Infect Dis. 1995;171:1504–13.PubMedGoogle Scholar
- Warren R, Hauman J, Beyers JN, Richardson M, Schaaf HS, Donald P, Unexpectedly high strain diversity of Mycobacterium tuberculosis in a high-incidence community. S Afr Med J. 1996;86:45–9.PubMedGoogle Scholar
- Das S, Paramasivan CN, Lowrie DB, Prabhakar R, Narayanan PR. IS6110 restriction fragment length polymorphism typing of clinical isolates of Mycobacterium tuberculosis from patients with pulmonary tuberculosis in Madras, South India. Tuber Lung Dis. 1995;76:550–4. DOIPubMedGoogle Scholar
- Yang ZH, de Haas PE, Wachmann CH, van Soolingen D, van Embden JD, Andersen AB. Molecular epidemiology of tuberculosis in Denmark in 1992. J Clin Microbiol. 1995;33:2077–81.PubMedGoogle Scholar
- Yang ZH, de Haas PE, van Soolingen D, van Embden JD, Andersen AB. Restriction fragment length polymorphism Mycobacterium tuberculosis strains isolated from Greenland during 1992: evidence of tuberculosis transmission between Greenland and Denmark. J Clin Microbiol. 1994;32:3018–25.PubMedGoogle Scholar
- Barnes PF, el-Hajj H, Preston-Martin S, Cave MD, Jones BE, Otaya M, Transmission of tuberculosis among the urban homeless. JAMA. 1996;275:305–7. DOIPubMedGoogle Scholar
- Gillespie SH, Kennedy N, Ngowi FI, Fomukong NG, al-Maamary S, Dale JW. Restriction fragment length polymorphism analysis of Mycobacterium tuberculosis isolated from patients with pulmonary tuberculosis in northern Tanzania. Trans R Soc Trop Med Hyg. 1995;89:335–8. DOIPubMedGoogle Scholar
- van Embden JD, Cave MD, Crawford JT, Dale JW, Eisenach KD, Gicquel B, Strain identification of Mycobacterium tuberculosis by DNA fingerprinting: recommendations for a standardized methodology. J Clin Microbiol. 1993;31:406–9.PubMedGoogle Scholar
- Woelffer GB, Bradford WZ, Paz A, Small PM. A computer-assisted molecular epidemiologic approach to confronting the reemergence of tuberculosis. Am J Med Sci. 1996;311:17–22. DOIPubMedGoogle Scholar
- Tenenbaum AM, Langsam Y, Augenstein MJ. Data structures using C. Englewood Cliffs (NJ): Prentice-Hall; 1990. p. 514-6.
Figures
Tables
Cite This ArticleTable of Contents – Volume 4, Number 2—June 1998
| EID Search Options |
|---|
|
|
|
|
|
|