Volume 11, Number 3—March 2005
Letter
Endogeneity in Logistic Regression Models
Cite This Article
Citation for Media
To the Editor: Ethelberg et al. (1) report on a study of the determinants of hemolytic uremic syndrome resulting from Shiga toxin–producing Escherichia coli. The dataset is relatively small, and the authors use stepwise logistic regression models to detect small differences. This indicates that the authors were aware of the limitations of the statistical power of the study. Despite this, the study has an analytical flaw that seriously reduces the statistical power of the study.
An often overlooked problem in building statistical models is that of endogeneity, a term arising from econometric analysis, in which the value of one independent variable is dependent on the value of other predictor variables. Because of this endogeneity, significant correlation can exist between the unobserved factors contributing to both the endogenous independent variable and the dependent variable, which results in biased estimators (incorrect regression coefficients) (2). Additionally, the correlation between the dependent variables can create significant multicollinearity, which violates the assumptions of standard regression models and results in inefficient estimators. This problem is shown by model-generated coefficient standard errors that are larger than true standard errors, which biases the interpretation towards the null hypothesis and increases the likelihood of a type II error. As a result, the power of the test of significance for an independent variable X1 is reduced by a factor of (1-r2(1|2,3,….)), where r(1|2,3,….) is defined as the multiple correlation coefficient for the model X1 = f(X2,X3,…), and all Xi are independent variables in the larger model (3,4).
The results of this study clearly show that the presence of bloody diarrhea is an endogenous variable in the model showing predictors of hemolytic uremic syndrome, in that the diarrhea is shown to be predicted by, and therefore strongly correlated with, several other variables used to predict hemolytic uremic syndrome. Similarly, Shiga toxin 1 and 2 (stx1, stx2) genes are expected to be key predictors of the presence of bloody diarrhea, independent of strain, due to the known biochemical effects of that toxin (5,6). Because the strain is in part determined by the presence of these toxins, including both strain and genotype in the model means that the standard errors for variables for the Shiga-containing strains and bloody diarrhea symptom are likely to be too high, and hence the significance levels (p values) obtained from the regression models are higher than the true probability because of a type I error.
This flaw is a particular problem with studies that use a conditional stepwise technique for including or excluding variables. The authors note that they excluded variables from the final model if the significance in initial models for those variables was less than an α level (p value) of 0.05. Given the inefficiencies due to the endogeneity of bloody diarrhea, as well as those that may result from other collinearities significant predictors were likely excluded from the study, although this cannot be confirmed from the data presented.
The problems associated with the endogeneity of bloody diarrhea can be overcome by a number of approaches. For example, the simultaneous equations approach, such as that outlined by Greene (7), would have used predicted values of bloody diarrhea from the first stage of the model as instrumental variables for the actual value in the model for hemolytic uremic syndrome. Structural equations approaches, such as those suggested by Greenland (8), would also be appropriate. However, bloody diarrhea is not the only endogenous variable in their models, and extensive modeling would be necessary to isolate the independent effects of the various predictor variables. Given the small sample size, this may not be possible.
Figure
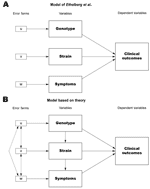
Figure. . Model for determining virulence factors for hemolytic uremic syndrome.
The underlying problem in the study is the theoretical specifications for the model, in which genotypes, strains, and symptoms are mixed, despite reasonable expectations that differences in 1 level may predict differences in another. For example, the authors’ data demonstrate that all O157 strains contain the stx2 gene and have higher rates of causing hemolytic uremic syndrome and bloody diarrhea. This calls into question the decision to build an analytic model combining 3 distinct levels of analysis. Such a model depends on the independence of the variables to gain unbiased, efficient estimators. The model of the relationships one would develop from a theoretical perspective would predict the opposite (Figure). We expect that the genotypes (by definition) will predict the strain, and that strains have a differential effect on symptoms. The high level of intervariable correlation due to these relationships, coupled with the decision to exclude variables based on likely inefficient p values, raises questions concerning the reliability of the results and conclusions. In particular, the conclusions that strains O157 and O111 are not predictors of hemolytic uremic syndrome deserve to be revisited; other excluded variables may also be significant predictors when considered under an appropriate model. These problems point to the need to ensure proper specification of analytic models and to demonstrate due regard for the underlying assumptions of statistical models used.
References
- Ethelberg S, Olson KEP, Schuetz F, Jensen C, Schiellerup P, Engberg J, Virulence factors for hemolytic uremic syndrome, Denmark. Emerg Infect Dis. 2004;10:842–7.PubMedGoogle Scholar
- Dowd B, Town R. Does X really cause Y? Washington: Academy Health; 2002.
- Hsieh F, Bloch D, Larsen M. A simple method of sample size calculation for linear and logistic regression. Stat Med. 1998;17:1623–34. DOIPubMedGoogle Scholar
- Menard S. Applied logistic regression analysis, 2nd ed. Thousand Oaks (CA): Sage Publications: 2002. p. 75–8.
- Blackall DP, Marques MB. Hemolytic uremic syndrome revisited: Shiga toxin, factor H, and fibrin generation. Am J Clin Pathol. 2004;121(Suppl):S81–8.PubMedGoogle Scholar
- Harrison LM, van Haaften WC, Tesh VL. Regulation of proinflammatory cytokine expression by Shiga toxin 1 and/or lipopolysaccharides in the human monocytic cell line THP-1. Infect Immun. 2004;72:2618–27. DOIPubMedGoogle Scholar
- Greene W. Gender economics courses in liberal arts colleges: further results. J Econ Educ. 1998;29:291–300.
- Greenland S, Brumback B. An overview of relations among causal modelling methods. Int J Epidemiol. 2002;31:1030–7. DOIPubMedGoogle Scholar
Figure
Cite This ArticleRelated Links
In response: We appreciate Avery's interest (1) in our article (2), although we believe the critique of the methods is largely based on misunderstandings. We developed a model for the risk of progression to hemolytic uremic syndrome (HUS) containing 3 variables: whether the infecting Shiga toxin–producing Escherichia coli isolate had the stx2 gene, age of the patient, and occurrence of bloody diarrhea. The critique relates to the fact that bloody diarrhea and stx2 are not independent, since we showed that stx2 was strongly associated with progression to HUS (odds ratio [OR] = 18.9) and also weakly associated with development of bloody diarrhea (OR = 2.5) (2). Avery uses the term endogeneity as it is used in econometric analyses; however, the term "intermediary variable," i.e., a factor in the causal pathway leading from exposure to disease, is more frequently used in epidemiology. In this context, we chose to consider bloody diarrhea as a potential confounder (3). A confounder is a risk factor but is also independently associated with the exposure variable of interest and is not regarded as part of the causal pathway (Figure). Bloody diarrhea may act as a confounder if patients with bloody stools are treated differently by the examining physicians or if, for instance, unknown virulence factors contribute to the risk of having bloody stools.
A second line of critique of our methods apparently develops from the idea that virulence factors determine the serogroup. This idea, however, is a biological misconception. In fact, virulence genes and serogroup are independent at the genetic level, and an important point of our article is that HUS is determined by the virulence gene composition of the strain rather than the serogroup.
Regardless of the status of the bloody diarrhea variable, excluding it from the model doesn't change the conclusions of the article. A revised model contains only the significant variables age and stx2 (Table). Serotype O157 is still not an independent predictor of HUS, and this result is robust.
References
- Avery G. Endogeneity in logistic regression models. Emerg Infect Dis. 2005;11:503-504.PubMedGoogle Scholar
- Ethelberg S, Olsen KE, Scheutz F, Jensen C, Schiellerup P, Enberg J, Virulence factors for hemolytic uremic syndrome, Denmark. Emerg Infect Dis. 2004;10:842–7.PubMedGoogle Scholar
- Griffin PM, Mead PS, Sivapalasingam S. Escherichia coli O157:H7 and other enterohaemorrhagic E. coli. In: Blaser MJ, Smith PD, Ravdin JI, Greenberg HB, Guerrant RL, editors. Infections of the gastrointestinal tract. Philadelphia: Lippincott Williams & Wilkins; 2002. p. 627–42.
Table of Contents – Volume 11, Number 3—March 2005
| EID Search Options |
|---|
|
|
|
|
|
|
Please use the form below to submit correspondence to the authors or contact them at the following address:
George Avery, 1207 Ordean Ct., BohH 320, University of Minnesota Duluth, Duluth, MI 55812, USA; fax: 218-726-7186
Steen Ethelberg, Department of Bacteriology, Mycology and Parasitology, Statens Serum Institut, Artillerivej 5, DK-2300 Copenhagen S, Denmark; fax: 45-3268-8238
Top