Volume 21, Number 3—March 2015
Research
Nanomicroarray and Multiplex Next-Generation Sequencing for Simultaneous Identification and Characterization of Influenza Viruses
Cite This Article
Citation for Media
Abstract
Conventional methods for detection and discrimination of influenza viruses are time consuming and labor intensive. We developed a diagnostic platform for simultaneous identification and characterization of influenza viruses that uses a combination of nanomicroarray for screening and multiplex next-generation sequencing (NGS) assays for laboratory confirmation. The nanomicroarray was developed to target hemagglutinin, neuraminidase, and matrix genes to identify influenza A and B viruses. PCR amplicons synthesized by using an adapted universal primer for all 8 gene segments of 9 influenza A subtypes were detected in the nanomicroarray and confirmed by the NGS assays. This platform can simultaneously detect and differentiate multiple influenza A subtypes in a single sample. Use of these methods as part of a new diagnostic algorithm for detection and confirmation of influenza infections may provide ongoing public health benefits by assisting with future epidemiologic studies and improving preparedness for potential influenza pandemics.
Influenza A virus consists of 8 negative, single-stranded RNA segments encoding 11 proteins: polymerase basic 1 and 2 (PB1 and PB2); polymerase acidic (PA); hemagglutinin (HA); nucleoprotein (NP); neuraminidase (NA); matrix (M1/2); and nonstructural (NS1/2). Influenza A viruses are classified into 18 HA subtypes (H1–H18) and 11 NA subtypes (N1–N11), determined on the basis of the antigenic differences in the surface glycoproteins HA and NA (1–4). All known HA subtypes of influenza A virus are found in aquatic birds, and some, including H1, H2, H3, H5, H7, and H9, have been reported to infect humans (1,5–7). Direct transmission of avian influenza A virus subtypes H5N1, H7N2, H7N3, H7N7, H9N2, and H10N7 from domestic poultry to humans has been reported (8–13).
In early 2009, a novel swine-origin virus, designated influenza A(H1N1)pdm09 (pH1N1), emerged in Mexico and spread rapidly around the world, causing a global influenza pandemic (14,15). This virus was generated by multiple reassortment events over 10 years (16,17) and continued to circulate in humans after the initial pandemic period, replacing the previously circulating seasonal H1N1 viruses. Influenza A(H3N2) variant virus (H3N2v) isolated from humans in the United States in 2011 was also generated through reassortment originating from swine, avian, and human viruses, including the M gene from pH1N1 virus (18,19). More recently, a novel avian-origin influenza A(H7N9) virus capable of poultry-to-human transmission was identified in China (7; http://www.who.int/influenza/human_animal_interface/influenza_h7n9/140225_H7N9RA_for_web_20140306FM.pdf). Diagnosis of infection with this virus is difficult because infection does not kill infected poultry, but the virus may post a substantial risk for a human pandemic because of a lack of immunity in the general population (7). As these viruses demonstrate, reassortment of pH1N1 virus with other circulating seasonal strains can produce virulent variants that can be transmitted to and among humans and that could emerge as a future pandemic strain (15,20,21). Therefore, it is critical to determine whether transmitted viruses have pandemic potential in humans during the influenza season.
Multiple influenza strains are usually prevalent during an influenza season. Increasing global travel results in rapid spread of novel influenza viruses from one geographic region to another (13,22). Current approaches for screening and characterizing novel influenza viruses require many steps and multiple assays. A single test has not been available for simultaneous identification of newly emerging strains from known or unknown subtypes of influenza viruses and the characterization of unique virulence factors or putative antiviral resistance markers.
We previously described a method for detection of avian influenza A(H5N1) and swine-origin pH1N1 viruses that used a nanotechnology-based, PCR-free, whole-genome microarray assay (nanomicroarray) (23,24). In this article, we describe a new diagnostic platform for identification and characterization of subtypes of influenza A virus that uses nanomicroarray for screening and multiplex next-generation sequencing (NGS) for laboratory confirmation. We demonstrate that this platform enables accurate and simultaneous identification of multiple subtypes in a single sample. We used this platform to evaluate clinical nasopharyngeal swab specimens from patients with influenza-like illness that had tested positive for influenza virus to determine influenza virus subtype.
Oligonucleotide Design and Nanomicroarray Assay
The sequences for multiple capture and intermediate oligonucleotides per target gene were designed and prepared as described previously (23,24). The oligonucleotide sequences and details of the nanomicroarray assays are listed and described in the Technical Appendix.
Viruses and Clinical Samples
Information about influenza viruses used in this study is provided in the online Technical Appendix. Nasopharyngeal swab specimens from patients with symptoms of influenza-like illness were submitted to the Clinical Virology Laboratory at Yale–New Haven Hospital, New Haven, Connecticut, USA, during December 27–December 31, 2012. Samples were tested by using direct fluorescent antigen (DFA) test with SimulFluor reagents (Millipore, Billerica, MA, USA) and, in some cases, by real-time reverse transcription PCR (rRT-PCR), as requested by the patients’ physicians. PCR was performed by using the Centers for Disease Control and Prevention rRT-PCR protocol for influenza as previously described (25). Samples for which DFA, rRT-PCR, or both gave results positive for influenza A were selected, de-identified, and sent to the Laboratory of Molecular Virology at the Food and Drug Administration in Silver Spring, Maryland, USA, for further testing (Table 1).
Viral RNA Extraction and rRT-PCR
A previously reported universal primer designed to amplify all 8 gene segments (26,27) was modified by adding 13-bp flanking sequence (5′-ACGACGGGCGACA-3′) at the 5′ end of each primer to enhance the annealing temperature and achieve high fidelity and yield in PCR amplification. Additional details of RNA extraction and rRT-PCR conditions are described in the Technical Appendix.
NGS Assay
The concentration of PCR amplicons of all 8 gene segments of influenza A virus was measured by using the Qubit dsDNA BR Assay System (Covaris, Woburn, MA, USA); 1 ng of DNA product was processed for NGS sample preparation by using a Nextera XT DNA Sample Preparation Kit (Illumina, San Diego, CA, USA), according to the manufacturer’s instructions. Briefly, the Nextera XT transposome fragmented PCR amplicons into a size of ≈500–700 bp and added adaptor sequences to the ends, enabling a 12-cycle PCR amplification to append additional unique dual index (i7 and i5) sequences at the end of each fragmented DNA for cluster formation. Mega-amplicons from influenza virus were internally marked with these dual-barcoded primers, which enabled multiplexing and simultaneous detection of different subtypes in the same run. After purification of PCR fragments and library normalization, sample pooling was performed by mixing equal volumes of each normalized DNA library, and the barcoded multiplexed library sequencing was performed on an Illumina MiSeq (Illumina). After automated cluster generation, sequencing was processed and genomic sequence reads obtained.
Bioinformatics Analysis
Sequencing reads of ≈300 bp were dynamically trimmed and sequence data were verified by FastQC software (http://www.bioinformatics.babraham.ac.uk/projects/fastqc/) before de novo assembly. The genome-contiguous assembly was constructed from MiSeq reads by using a de novo module in CLC genomics workbench software version 6.0.2 (CLC bio, Cambridge, MA, USA); minimum contiguous length was set at 800 for assembling consensus sequences (28). A comprehensive-read database was generated for the whole genome of the influenza virus tested. Sequences were further filtered so that the local database contained only 1 unique contig for each gene segment, and multiple contigs were generated for each sample. These representative sequences comprise the set of unique sequences from the dataset. A FASTA file with all unique contiguous sequences of each mega-amplicon was used to perform an all-by-all Identify Similae Sequences search in the Influenza Research Database (IRD, http://www.fludb.org), the Global Initiative on Sharing All Influenza Data database (http://platform.gisaid.org), and the National Center for Biotechnology Information database (http://www.ncbi.nlm.nih.gov). The top-scoring BLAST (http://blast.ncbi.nlm.nih.gov/) match was selected to identify the specific genome. Assembled sequences were aligned in ClustalW (http://www.clustal.org), and phylogenetic analysis was performed in MEGA by using the neighbor-joining method (29). All amplicons were accurately categorized into a typical subtype.
Verification of Capture and Intermediate Oligonucleotides
A nanomicroarray for each target gene was designed, printed in-house, and tested separately by using the PCR products as templates to verify the ability of individual capture and intermediate oligonucleotides to detect a specific target gene. Ineffective capture oligonucleotides were replaced and retested. We amplified PCR products of HA, NA, and M genes for H7N2, H7N3, and H9N2 viruses separately or simultaneously in a single reaction using the corresponding 3 sets of specific primers. To identify the correct HA and NA gene segments for multiplex influenza subtyping, we fabricated a new nanomicroarray by pooling autologous 4 to 5 capture oligonucleotides for a specific gene and then printing them on the array substrate in triplicates. Each nanomicroarray subarray contains multiple gene spots for multiplex assays. The PCR products were hybridized on the array, and the specific signal profiles were correctly observed in the areas printed with corresponding gene-specific capture oligonucleotides (Technical Appendix Figure 1). No interference or cross-hybridization was observed when multiple targets and intermediate oligonucleotides were included in the assay. The specific signal pattern showed the assay’s ability to accurately discriminate influenza subtypes.
Amplification of Whole-Genome Segments
To further confirm subtypes detected in the nanomicroarray screening assay for final laboratory diagnosis, we redesigned universal primers to amplify whole-genome segments and separately tested 22 influenza A strains covering 10 subtypes and 3 influenza B viruses. All 8 segments of influenza A viruses were simultaneously amplified in a single reaction, resulting in multiple PCR products ranging in size from 500 to 2,500 bp (mega-amplicons). We also tested 3 influenza B viruses, B/Brisbane/60/2008 (Victoria lineage), B/Pennsylvania/7/2007 (Yamagata lineage), and B/Victoria/304/2006 (Victoria lineage), and 2 influenza A viruses, A/Panama/2007/1999 (H1N1) and A/ruddy turnstone/NJ/65/1985 (H7N3), and found several faint, nonspecific small bands no larger than 1 kb (data not shown).
Evaluation of Nanomicroarray Assay by using PCR Mega-amplicons
Figure 1
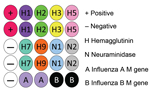
Figure 1. Nanomicroarray layout design for testing of samples for influenza A and B viruses. The microarray internal positive control capture is listed in Technical Appendix Table 1. The negative...
Figure 2
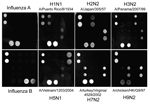
Figure 2. Portion of the microarray images for DNA oligonucleotides of influenza viruses after hybridization with PCR products. Lighter shades represent greater silver intensities for each gene. Typical nanomicroarray silver staining images represent...
To include M gene capture oligonucleotides for influenza B viruses, we developed a new nanomicroarray (Figure 1). As shown in Figure 2, amplified PCR products of the matrix gene from influenza A and B viruses were specifically detected in the correct spot areas without cross-hybridization. The mega-amplicons of influenza A viruses were correctly identified and found to have a unique fingerprint for each influenza A virus tested. Each spot pattern represented a typical influenza virus subtype corresponding to the gene-specific capture oligonucleotides. We conclude that the current nanomicroarray assay can simultaneously discriminate influenza A from B viruses and specifically identify influenza A subtypes H1, H2, H3, H5, H7, H9, N1, N2, and N3.
NGS Confirmation of Influenza A Subtypes
A total of 17 mega-amplicons representing 10 subtypes of influenza A and 1 of influenza B were tested in the NGS assay. Multiple contiguous sequences were created automatically for each mega-amplicon by using a de novo assembly program in CLC, and 4–8 contigs supported by high coverage rate of sequence reads were generated (Technical Appendix Table 2). The mega-amplicons of the A/Vietnam/1204/2004 (H5N1) strain yielded 8 contiguous sequences supported by 90,962 reads. Further BLAST search of 8 contiguous sequences in the IRD resulted in 8 mast BLAST reports. All contiguous sequences were found to correspond to 6 proteins (PB2, PB1, PA, NP, M, and NS) of A/Puerto Rico/8/1934 (H1N1) virus and 2 proteins (HA/CIP045/CY077101 and NA/HM006761) of A/Vietnam/1203/2004 (H5N1) with 99%–100% sequence identity. These results showed that all amplicons were correctly identified as the H5N1 laboratory strain.
The mega-amplicons from A/turkey/Virginia/4529/2002 (H7N2) and A/Minnesota/10/2012 (H3N2) strains resulted in 8 contigs, all correctly identified as the correct subtype. We found strong concordance in contiguous sequences and PCR fragments for each mega-amplicon. A de novo assembly program generated at least 7 contigs from faint band mega-amplicons for influenza B virus (B/Brisbane/60/2008); 2 showed good coverage (7,077 and 10,168), but the BLAST search indicated that none matched the gene sequence from this strain. Further investigation using freshly extracted RNA may be required.
Simultaneous NGS Discrimination of Multiple Subtypes in a Single Sample
We tested 4 influenza viruses obtained from the Centers for Disease Control and Prevention, A/Puerto Rico/8/1934 (H1N1), A/Vietnam/1203/2004 (H5N1), A/Minnesota/10/2012 (H3N2), and A/Anhui/1/2013 (H7N9), to determine the presence of H1, H3, H5, H7, N1, N2, and N9 subtypes. RNA was extracted from individual or mixed viral strains. The universal rRT-PCR was performed to amplify whole-genome segments in which the PCR mega-amplicons represented a similar pattern to individual or mixed viral samples (Technical Appendix Figure 2). After the NGS assay followed by de novo assembly, 8 contigs were generated for the H5N1 and H3N2 viruses, and 15 contigs were generated for the mixed sample, supported by a high coverage rate of reads (Table 2). These 15 contigs from mixed samples exactly matched the gene segments of the H5N1 and H3N2 strains, similar to the results obtained with the individual sample, as expected. HA and NA genomic sequences of the H7N9 subtype virus were identified as strain A/Anhui/1/2013 from the Global Initiative on Sharing All Influenza Data database. Because PB2 (2,341 bp), PB1 (2,341 bp), and PA (2,233 bp) genes have very similar sizes, direct separation of each gene from co-infected samples is not possible by conventional sequencing methods. These findings demonstrated that the NGS assay can simultaneously identify and confirm the presence of >1 influenza subtypes in a single sample.
Evaluation of Nasopharyngeal Swab Samples by using NGS Assays
We performed universal RT-PCR and NGS assays on 24 nasopharyngeal swab samples obtained from patients who had received a diagnosis of influenza. These samples were initially tested by DFA, rRT-PCR, or both and found to be positive for influenza A virus. After decoding, all samples were found to be positive by using the universal RT-PCR detection method, indicating presence of influenza A infection (Table 1). When mega-amplicons representing the 24 patient samples were tested in the NGS, a total of 32.8 million reads were obtained, and multiple contigs were generated for each sample (Technical Appendix Table 3). A BLAST search of each contig in the IRD database identified the genome corresponding to the influenza A(H3N2) subtype. The coverage of influenza A(H3N2) genomes in the NGS assay was 96.7% (31.7/32.8 million) of raw reads and 76.6% (183/239) of total contigs. A total of 95.3% (183/192 contigs) of the influenza A(H3N2) genome was amplified and sequenced; the average depth of coverage for each contig was 3,259. Of these genomes, 71% (136/192) of segments yielded full-length sequences; HA genes were 96% (23/24); NP, 96% (23/24); NA, 88% (21/24); M, 88%, (21/24); and NS, 79% (19/24). The average breadth of coverage was 100% for HA, NA, NP, M, and NS genes and 93% for PB2, PB1, and PA genes.
Figure 3

Figure 3. Phylogenetic analysis of the matrix (M) gene sequences obtained from nasopharyngeal swab samples from patients who had received a diagnosis of influenza in Connecticut, USA, during the 2012–13 influenza season (see...
Phylogenetic analysis of each of the 8 segments separately for all isolates showed that all genes clustered together in the H3N2 radiation with a high bootstrap value (data not shown). None of the M genes closely clustered with the M genes from the pH1N1 or H3N2v viruses (Figure 3), which suggests that these viruses are not H3N2v (18,19). The genotype of 24 influenza A(H3N2) viruses was determined as [A,D,B,3A,A,2A,B,1A] by using FluGenotyping (http://www.flugenome.org), which indicates that the same lineage virus is circulating in this region. The HA genes from most samples shared very high identity with A/Boston/DOA2–206/2013(H3N2) and the NA genes with A/Boston/DOA2-141/2013(H3N2) strain. After completing these analyses, 181 gene sequences were deposited into GenBank (accession nos. KJ741883–KJ742063).
We report the development of a novel diagnostic platform for simultaneous detection, typing, and whole-genome characterization of influenza viruses that uses a combination of nanomicroarray and high-throughput NGS approaches. First, we designed capture and intermediate oligonucleotides for H1, H2, H3, H5, H7, H9, N1, N2, and N3 of influenza A virus and M genes of influenza B virus and evaluated these oligonucleotides in a nanomicroarray assay. Second, we modified previously reported universal primers (26,27) and used them to amplify the whole genome of influenza A viruses for validation of the nanomicroarray assay. Finally, we confirmed results by using the NGS assay. This protocol enables random accessing of a variety of target genes for simultaneous identification and final sequence-based confirmation of influenza virus infection.
Designing multiple capture and intermediate oligonucleotides with sequences covering the entire genome ensures specific capture of multiple target genes on the nanomicroarray and subsequent detection with a universal nanoparticle probe regardless of mutation, deletion, and influenza reassortment. Furthermore, this design is adaptable for other applications and enables direct detection and subtyping of an unknown sample without previous knowledge of types and subtypes. In the current format, >50 degenerate capture oligonucleotides cover 12 influenza viral target genes, enabling direct detection of any combination of ≈20 subtypes in a single sample, identification of influenza A subtypes in a single assay, and differentiation of influenza A from B viruses. An optimal nanomicroarray assay, which is a reformatted portable device modified for use in point-of-care settings, should include target genes from most influenza A and B viruses as well as for other respiratory viral pathogens. The assay should be easily performed by an untrained technician for sample testing in the field without enzymatic reactions, and results should be in a form that can easily be visualized by the naked eye. In comparison to other conventional detection methods for targeting each gene of influenza A and B viruses separately, the nanomicroarray assay is a one-test-fits-all approach for diagnosis of influenza virus infections that can provide results in <1.5 hours, making this method relatively cost- and time-effective. More important, the nanomicroarray assay can detect emerging and reassortant viruses, and those samples can be sent to centralized laboratories that perform the NGS assay for final sequence confirmation.
Gene segments in most influenza viruses isolated from humans can be adapted from animals, as shown by genetic changes in influenza A(H7N9) isolates from poultry and humans (7,30). These studies indicated that more changes were acquired during the human infection process. Determining the nature and frequency of co-infection associated with influenza A virus will be critical if an unknown sample contains a novel strain or >1 HA or NA gene subtype. NGS is a powerful tool facilitating diagnosis on a large scale, including high-throughput and simultaneous identification of >96 samples barcoded by using dual index primers and detection of >9,216 genes in a single sequencing run. By using a universal primer adapted to fabricate the mega-amplicons, we showed that the NGS assay is capable of accurately subtyping any influenza A virus and detecting multiple known and unknown influenza genes in a single assay. Bioinformatic skills and mathematics tools, combined with epidemiologic studies, are useful in facilitating prediction of potential subtypes according to the genetic matrix composition of influenza genomic segments for a new, emerging, and reassorted strain whereby the subtypes can be confirmed (31–34). Influenza A viruses representing 11 subtypes were accurately detected in this study, and the 2 mixed influenza viruses were discriminated by using this sequencing-based diagnostic platform.
Sequence analysis of 24 clinical samples revealed that 23 (92%) segments contained an amino acid substitution at position E627K in PB2 gene. Mutation of glutamic acid (E) at PB2 residue 627 to lysine (K) favors adaptation to the mammalian host; such mutations have been found in human isolates of highly pathogenic avian influenza viruses of the H7N7 and H7N9 subtypes (7,35,36). These mutations might confer high virulence to the virus by enhancing replication efficiency, increasing polymerase activity and disease severity of avian influenza viruses in mammals (37).
Of the 24 M genes of the samples we tested, 21 (88%) had a single S31N mutation in the transmembrane region of the M2 protein, which has been found to confer resistance to amantadine (7,38). The emergence of E627K(PB2) and S31N(M2) mutations in tested samples suggests that human host infection in the Connecticut region in the 2012–2013 seasons might be poultry-to-human transmission associated with disease severity (39,40). This observation highlights an increased risk to public health and the need to continually monitor isolates obtained from mammal reservoirs for genetic variation. This information may help guide clinical treatment and assessment of epidemiology during the epidemic season.
The assay we evaluated is a minimally manipulated procedure that greatly reduces the number of amplifications and omits fragment separation and purification. It is therefore suitable for identification of any strains of influenza virus. An ongoing study using this assay has simultaneously detected and confirmed influenza A(H3N2), pH1N1, and influenza B viruses in >100 nasopharyngeal swab samples (J. Zhao et al., unpub. data).
Figure 4
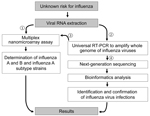
Figure 4. Diagnostic algorithm for identification of an unknown risk for influenza by using nanomicroarray and next-generation sequencing (NGS) assays. To determine the virus type for a suspected influenza virus infection, viral RNA...
This detection platform provides a new, accurate, and rapid method to refine the differential diagnosis of influenza by selecting a single test or a small set of tests to determine the strain or strains present in a single clinical sample. We propose a new diagnostic algorithm based on this combined platform for identification and characterization of infection risks of unknown influenza strains (Figure 4). For testing a suspected influenza virus infection, this detection platform takes 2–3 days to perform NGS assay and data analysis. However, it provides whole-genome characterization and a final report in matrix type by which a potential pandemic prevalence strain can be predicted, with data including the genetic variant, amino acid signatures for virulence factors, and drug-resistance– and host-adaptation–associated mutations.
Future studies need to be conducted to reformat the current microarray to a point-of-care setting and to expand testing of clinical samples to other geographic regions and additional influenza virus types/subtypes. The NGS assay involves sample preparation and generates massive sequence data for the final report for test interpretation, which requires a higher level of performance for clinical assay validation. Development of an automated assembly and analysis pipeline can make the bioinformatics analysis of transferring raw reads to the specific genomic identification more efficient. This molecular diagnostic platform has the potential for monitoring newly emerging or re-emerging viral reassortants derived from different precursors and could be included as a part of pandemic influenza surveillance strategies for efficient prevention and timely implementation of treatment to protect and improve public health.
Dr Zhao is a virologist and reviewer at the Food and Drug Administration, Silver Spring, Maryland. His research interests include new technologies and tools for diagnosis of infectious viral pathogens.
Acknowledgments
We are thankful to FDA Center for Biologics Evaluation and Research core facility staff for help with some NGS assays and oligosynthesis.
This work was funded through the FDA Center for Biologics Evaluation and Research intramural and Medical Countermeasures Initiative funds.
The findings and conclusions in this article have not been formally disseminated by the Food and Drug Administration and should not be construed to represent any Agency determination or policy.
References
- Webster RG, Bean WJ, Gorman OT, Chambers TM, Kawaoka Y. Evolution and ecology of influenza A viruses. Microbiol Rev. 1992;56:152–79 .PubMedGoogle Scholar
- Röhm C, Zhou N, Suss J, Mackenzie J, Webster RG. Characterization of a novel influenza hemagglutinin, H15: criteria for determination of influenza A subtypes. Virology. 1996;217:508–16. DOIPubMedGoogle Scholar
- Fouchier RA, Munster V, Wallensten A, Bestebroer TM, Herfst S, Smith D, Characterization of a novel influenza A virus hemagglutinin subtype (H16) obtained from black-headed gulls. J Virol. 2005;79:2814–22. DOIPubMedGoogle Scholar
- Tong S, Zhu X, Li Y, New world bats harbor diverse influenza A viruses. PLoS Pathog. 2013;9:e1003657. DOIPubMedGoogle Scholar
- Horimoto T, Kawaoka Y. Pandemic threat posed by avian influenza A viruses. Clin Microbiol Rev. 2001;14:129–49. DOIPubMedGoogle Scholar
- Hilleman MR. Realities and enigmas of human viral influenza: pathogenesis, epidemiology and control. Vaccine. 2002;20:3068–87. DOIPubMedGoogle Scholar
- Gao R, Cao B, Hu Y, Feng Z, Wang D, Hu W, Human infection with a novel avian-origin influenza A (H7N9) virus. N Engl J Med. 2013;368:1888–97. DOIPubMedGoogle Scholar
- Arzey GG, Kirkland PD, Arzey KE, Frost M, Maywood P, Conaty S, Influenza virus A (H10N7) in chickens and poultry abattoir workers, Australia. Emerg Infect Dis. 2012;18:814–6. DOIPubMedGoogle Scholar
- Cheng VC, Chan JF, Wen X, Wu WL, Que TL, Chen H, Infection of immunocompromised patients by avian H9N2 influenza A virus. J Infect. 2011;62:394–9. DOIPubMedGoogle Scholar
- Koopmans M, Wilbrink B, Conyn M, Natrop G, van der Nat H, Vennema H, Transmission of H7N7 avian influenza A virus to human beings during a large outbreak in commercial poultry farms in the Netherlands. Lancet. 2004;363:587–93. DOIPubMedGoogle Scholar
- Ostrowsky B, Huang A, Terry W, Anton D, Brunagel B, Traynor L, Low pathogenic avian influenza A (H7N2) virus infection in immunocompromised adult, New York, USA, 2003. Emerg Infect Dis. 2012;18:1128–31. DOIPubMedGoogle Scholar
- Tweed SA, Skowronski DM, David ST, Larder A, Petric M, Lees W, Human illness from avian influenza H7N3, British Columbia. Emerg Infect Dis. 2004;10:2196–9. DOIPubMedGoogle Scholar
- Pabbaraju K, Tellier R, Wong S, Li Y, Bastien N, Tang JW, Full-genome analysis of avian influenza A(H5N1) virus from a human, North America, 2013. Emerg Infect Dis. 2014;20:887–91. DOIPubMedGoogle Scholar
- Gallaher WR. Towards a sane and rational approach to management of influenza H1N1 2009. Virol J. 2009;6:51. DOIPubMedGoogle Scholar
- Vijaykrishna D, Poon LL, Zhu HC, Ma SK, Li OT, Cheung CL, Reassortment of pandemic H1N1/2009 influenza A virus in swine. Science. 2010;328:1529. DOIPubMedGoogle Scholar
- Smith GJ, Vijaykrishna D, Bahl J, Lycett SJ, Worobey M, Pybus OG, Origins and evolutionary genomics of the 2009 swine-origin H1N1 influenza A epidemic. Nature. 2009;459:1122–5. DOIPubMedGoogle Scholar
- Garten RJ, Davis CT, Russell CA, Shu B, Lindstrom S, Balish A, Antigenic and genetic characteristics of swine-origin 2009 A(H1N1) influenza viruses circulating in humans. Science. 2009;325:197–201. DOIPubMedGoogle Scholar
- Lindstrom S, Garten R, Balish A, Shu B, Emery S, Berman L, Human infections with novel reassortant influenza A(H3N2)v viruses, United States, 2011. Emerg Infect Dis. 2012;18:834–7. DOIPubMedGoogle Scholar
- Nelson MI, Vincent AL, Kitikoon P, Holmes EC, Gramer MR. Evolution of novel reassortant A/H3N2 influenza viruses in North American swine and humans, 2009–2011. J Virol. 2012;86:8872–8. DOIPubMedGoogle Scholar
- Kitikoon P, Vincent AL, Gauger PC, Schlink SN, Bayles DO, Gramer MR, Pathogenicity and transmission in pigs of the novel A(H3N2)v influenza virus isolated from humans and characterization of swine H3N2 viruses isolated in 2010–2011. J Virol. 2012;86:6804–14. DOIPubMedGoogle Scholar
- Webby RJ, Webster RG. Emergence of influenza A viruses. Philos Trans R Soc Lond B Biol Sci. 2001;356:1817–28. DOIPubMedGoogle Scholar
- Chang SY, Lin PH, Tsai JC, Hung CC, Chang SC. The first case of H7N9 influenza in Taiwan. Lancet. 2013;381:1621. DOIPubMedGoogle Scholar
- Zhao J, Wang X, Ragupathy V, Zhang P, Tang W, Ye Z, Rapid detection and differentiation of swine-origin influenza a virus (H1N1/2009) from other seasonal influenza A viruses. Viruses. 2012;4:3012–9. DOIPubMedGoogle Scholar
- Zhao J, Tang S, Storhoff J, Marla S, Bao YP, Wang X, Multiplexed, rapid detection of H5N1 using a PCR-free nanoparticle-based genomic microarray assay. BMC Biotechnol. 2010;10:74. DOIPubMedGoogle Scholar
- Landry ML, Ferguson D. Cytospin-enhanced immunofluorescence and impact of sample quality on detection of novel swine origin (H1N1) influenza virus. J Clin Microbiol. 2010;48:957–9. DOIPubMedGoogle Scholar
- Zhou B, Donnelly ME, Scholes DT, St George K, Hatta M, Kawaoka Y, Single-reaction genomic amplification accelerates sequencing and vaccine production for classical and swine origin human influenza a viruses. J Virol. 2009;83:10309–13. DOIPubMedGoogle Scholar
- Hoffmann E, Stech J, Guan Y, Webster RG, Perez DR. Universal primer set for the full-length amplification of all influenza A viruses. Arch Virol. 2001;146:2275–89. DOIPubMedGoogle Scholar
- Treangen TJ, Salzberg SL. Repetitive DNA and next-generation sequencing: computational challenges and solutions. Nat Rev Genet. 2012;13:36–46.PubMedGoogle Scholar
- Tamura K, Dudley J, Nei M, Kumar S. MEGA4: molecular evolutionary genetics analysis (MEGA) software version 4.0. Mol Biol Evol. 2007;24:1596–9. DOIPubMedGoogle Scholar
- Chen Y, Liang W, Yang S, Wu N, Gao H, Sheng J, Human infections with the emerging avian influenza A H7N9 virus from wet market poultry: clinical analysis and characterisation of viral genome. Lancet. 2013;381:1916–25. DOIPubMedGoogle Scholar
- Yurovsky A, Moret BM. FluReF, an automated flu virus reassortment finder based on phylogenetic trees. BMC Genomics. 2011;12(Suppl 2):S3. DOIPubMedGoogle Scholar
- Rabadan R, Levine AJ, Krasnitz M. Non-random reassortment in human influenza A viruses. Influenza Other Respir Viruses. 2008;2:9–22.
- Lun AT, Wong JW, Downard KM. FluShuffle and FluResort: new algorithms to identify reassorted strains of the influenza virus by mass spectrometry. BMC Bioinformatics. 2012;13:208. DOIPubMedGoogle Scholar
- Jonges M, Meijer A, Fouchier RA, Koch G, Li J, Pan JC, Guiding outbreak management by the use of influenza A(H7Nx) virus sequence analysis. Euro Surveill. 2013;18:20460 .PubMedGoogle Scholar
- Munster VJ, de Wit E, van Riel D, Beyer WE, Rimmelzwaan GF, Osterhaus AD, The molecular basis of the pathogenicity of the Dutch highly pathogenic human influenza A H7N7 viruses. J Infect Dis. 2007;196:258–65. DOIPubMedGoogle Scholar
- Mok CK, Lee HH, Lestra M, Nicholls JM, Chan MC, Sia SF, Amino acid substitutions in polymerase basic protein 2 gene contribute to the pathogenicity of the novel A/H7N9 influenza virus in mammalian hosts. J Virol. 2014;88:3568–76. DOIPubMedGoogle Scholar
- Hatta M, Gao P, Halfmann P, Kawaoka Y. Molecular basis for high virulence of Hong Kong H5N1 influenza A viruses. Science. 2001;293:1840–2. DOIPubMedGoogle Scholar
- Zaraket H, Saito R, Suzuki Y, Suzuki Y, Caperig-Dapat I, Dapat C, Genomic events contributing to the high prevalence of amantadine-resistant influenza A/H3N2. Antivir Ther. 2010;15:307–19. DOIPubMedGoogle Scholar
- Liu Q, Lu L, Sun Z, Chen GW, Wen Y, Jiang S. Genomic signature and protein sequence analysis of a novel influenza A (H7N9) virus that causes an outbreak in humans in China. Microbes Infect. 2013;15:432–9. DOIPubMedGoogle Scholar
- Chen Y, Liang W, Yang S, Wu N, Gao H, Sheng J, Human infections with the emerging avian influenza A H7N9 virus from wet market poultry: clinical analysis and characterization of viral genome. Lancet. 2013;381:1916–25. DOIPubMedGoogle Scholar
Figures
Tables
Cite This ArticleTable of Contents – Volume 21, Number 3—March 2015
| EID Search Options |
|---|
|
|
|
|
|
|
Please use the form below to submit correspondence to the authors or contact them at the following address:
Jiangqin Zhao or Indira Hewlett, Laboratory of Molecular Virology, CBER/FDA, Bldg 52/72, Rm 4308, 10903 New Hampshire Ave, Silver Spring, MD 20993-0002, USA; or
Top