Volume 27, Number 1—January 2021
Research
Performance of Nucleic Acid Amplification Tests for Detection of Severe Acute Respiratory Syndrome Coronavirus 2 in Prospectively Pooled Specimens
Cite This Article
Citation for Media
Abstract
Pooled nucleic acid amplification tests for severe acute respiratory syndrome coronavirus 2 could increase availability of testing at decreased cost. However, the effect of dilution on analytical sensitivity through sample pooling has not been well characterized. We tested 1,648 prospectively pooled specimens by using 3 nucleic acid amplification tests for severe acute respiratory syndrome coronavirus 2: a laboratory-developed real-time reverse transcription PCR targeting the envelope gene, and 2 commercially available Panther System assays targeting open reading frame 1ab. Positive percent agreement (PPA) of pooled versus individual testing ranged from 71.7% to 82.6% for pools of 8 and from 82.9% to 100.0% for pools of 4. We developed and validated an independent stochastic simulation model to estimate effects of dilution on PPA and efficiency of a 2-stage pooled real-time reverse transcription PCR testing algorithm. PPA was dependent on the proportion of tests with positive results, cycle threshold distribution, and assay limit of detection.
The ability of clinical laboratories to meet the demand for severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) testing is critical for reducing coronavirus disease (COVID-19)–related illness, death, and economic impact. Pooled testing has the potential to decrease resources required for population-level screening and can provide valuable data to inform public health policies (1,2). Several previous experimental and modeling studies have demonstrated the feasibility of pooled SARS-CoV-2 nucleic acid amplification testing (NAAT), in pools of <32 individual samples (3–9). However, the potential increase in efficiency gained by pooled testing is offset by a theoretical dilution-related decrease in analytical sensitivity (8,10).
Despite this decrease in sensitivity, pooled testing of blood donors for transfusion-transmitted infections, such as those with HIV-1 and hepatitis C virus, has proven to be safe and effective (11). This efficacy varies depending on the performance characteristics of the assay, the prevalence of infection, viral load kinetics, and pooling size, and strategy. For agents with variable seasonal or geographic prevalence, such as West Nile virus, many blood banks use adaptive risk-based pooling strategies, switching from pooled to individual testing when there is an increase in regional prevalence (12). Adapting a similar risk-based pooling strategy for SARS-CoV-2 has the potential to enable more widespread testing of high-risk populations and asymptomatic critical infrastructure workers, guide aggressive contact-tracing measures, and help direct public health interventions to where they are most needed. However, there are limited prospective data on assay-specific performance characteristics of pooled testing to guide implementation of such a strategy. Furthermore, there is little evidence on parallel test performance of different assays on pooled samples to direct choice of method.
In this study, we aimed to evaluate the test performance characteristics of 1 laboratory-developed and 2 commercially available SARS-CoV-2 NAATs for 1,648 individual respiratory specimens prospectively grouped in pools of 8 and 4. We used these data to validate a stochastic model to estimate optimal pool size, efficiency, and expected positive percent agreement (PPA) of a 2-stage pooled testing algorithm that takes into account prevalence, viral load distribution, and assay analytical sensitivity.
Clinical Specimens
The Stanford Clinical Virology Laboratory receives samples from tertiary-care academic hospitals and affiliated outpatient facilities in the San Francisco Bay Area of California. Prospective pooling of consecutive nasopharyngeal or oropharyngeal swab specimens submitted for SARS-CoV-2 testing during the morning shift was conducted during June 10–19, 2020, for evaluation of a pool size of 8 and during July 6–July 23, 2020, for evaluation of a pool size of 4. Samples submitted for testing were collected from symptomatic and asymptomatic inpatients and outpatients, either for clinical care or in the context of COVID-related epidemiologic surveillance studies and drug trials at our institution. As samples from persons enrolled in these studies and trials were received daily in batches, they were randomly evenly distributed among pools on a daily basis. This distribution was conducted to preserve the independence between samples in the same pool; these samples had not been tested before receipt in our laboratory and were otherwise treated identically to nonresearch samples. Nonresearch samples were otherwise assigned to pools consecutively. Additional laboratorywide data on proportion of tests positive and cycle threshold (Ct) value distribution were obtained from all specimens (n = 74,162) tested during March 1–June 24, 2020. This study was conducted with Stanford institutional review board approval (protocol no. 48973), and individual consent was waived.
Pool Size Determination
In this study, an initial pool size of 8 was selected on the basis of pilot experiments with pool sizes ranging from 4 to 10 (B.A. Pinsky, unpub. data), and the logistical consideration that pooling in multiples of 4 would be more efficient for the robotic liquid handlers in our laboratory. After review of the test performance characteristics of 8-sample pooling in conjunction with the results of an independent stochastic simulation model, additional testing was performed to evaluate a pool size of 4 to generate empiric data for further model validation. Subset analyses of first tests versus follow-up tests were conducted by retrospectively assigning pools to 1 of the 2 groups on the basis of the status of the positive sample(s) in that pool. Pools containing positive samples belonging to both groups were excluded from this analysis. To validate the performance of the model for additional pool sizes, an external in silico dataset was obtained on the basis of pool sizes of 3 and 5. The in silico analysis was performed according to US Food and Drug Administration recommendations (Appendix) (13).
Sample Pooling, Extraction, and NAAT
Pools were constructed before nucleic acid extraction by combining 500 μL from each of the individual samples. For a pool size of 8, this resulted in a total volume of 4 mL and a dilution factor of 1:8. For a pool size of 4, this resulted in a total volume of 2 mL and a dilution factor of 1:4.
Subsequently, total nucleic acids were extracted from 500 μL taken from each pool and each individual specimen by using QIAsymphony and the QIAsymphony DSP Virus/Pathogen Midi Kit (QIAGEN, https://www.qiagen.com) and eluted into 60 μL of AVE buffer according to manufacturer’s instructions. Real-time reverse transcription PCR (rRT-PCR) was performed by using an emergency use authorization laboratory-developed test (LDT) targeting the envelope gene with the Rotor-Gene Q Instrument (QIAGEN) as described (14–16), with pooled samples tested on the same run as component individual samples. A Ct result of 40–45 was considered an indeterminate result, which was adjudicated by repeat testing and resulted as positive if reproducible with an acceptable amplification curve. Specimens were only reported as negative if the internal control human RNase P gene was detected at a Ct<35.
On the same day as QIAsymphony extraction, another 500 μL from each pool was transferred to a Hologic Panther Specimen Lysis Tube (Hologic, https://www.hologic.com) and tested by using the Panther Fusion SARS-CoV-2 Assay (Hologic) and Panther Aptima SARS-CoV-2 assay (Hologic) per the manufacturer’s recommendations (17,18). In addition to the manufacturer-set cutoff value, receiver operating characteristic (ROC) curve analysis of pooled relative light unit (RLU) values, with individual test results as the reference method, was used to determine the optimal RLU discrimination threshold. A focused electronic medical record review was conducted for all samples.
Statistical Analysis
ROC curve analysis was conducted by using R package pROC (19). PPA and negative percent agreement (NPA) were calculated by using individual testing as the reference method and were reported with exact (Clopper-Pearson) 95% CIs (20). Passing-Bablok regression was used to compare Ct values of the individual LDT, pooled LDTs, and pooled Panther Fusion assays. The 95% CIs of slope, intercept, and bias were calculated by using an ordinary nonparametric bootstrap resampling method with default parameters in R package mcr. Paired t-tests were used to compare the mean differences between paired Ct values among different assays. A Student t-test was used to compare the mean difference between internal control RNase P Ct values in false-negative and true-negative pools. All comparisons were 2-sided with type I error set at 0.05. We used the laboratory-wide Ct value distribution and a separate limit of detection (LoD) experiment to develop a stochastic simulation model to estimate PPA and efficiency for a 2-stage pooled testing algorithm, which was subsequently validated by using the independent empiric pools of 8 and pools of 4 data, as well as in silico pools of 5 and pools of 3 data. We provide the methods used to develop this model (Appendix).
Assay Comparisons for Pools of 8
Figure 1

Figure 1. Performance of nucleic acid amplification tests for detection of severe acute respiratory syndrome coronavirus 2 in prospectively pooled specimens. For a pool size of 8, paired individual and pooled C...
To evaluate a pool size of 8, a total of 112 pools from 896 samples were each tested on 3 different NAAT platforms (Table 1). Two pools were invalid, 1 by the Panther Fusion assay (0.9%), and 1 by the Panther Aptima assay (0.9%), and were excluded from subsequent analysis. All 16 individual samples in these 2 pools showed negative results. The remaining 110 pools contained 880 individual samples. Four samples were tested in duplicate in 2 different pools and showed identical results. Among the 880 individual samples, 58 (6.6%) showed positive results and a median Ct value of 31.4 (interquartile range 22.1–35.5). First-time diagnostic specimens had a higher median Ct value than specimens that underwent follow-up tests (Table 2). ROC curve analysis for the Panther Aptima showed optimal cutoff values between 343 and 393 RLUs; a cutoff value of 350 was chosen as the nearest round number (Panther Aptima-350) (Appendix Table 1, Figure 1).
Among the tested pools of 8, a total of 41.8% (46/110) contained >1 positive sample. The positive pools comprised 36 pools with 1 positive sample, 9 pools with 2 positive samples, and 1 pool with 4 positive samples (Table 3). There were 3 false-positive pools, 1 on each platform, in which each of the individual samples showed negative results. The overall PPA of pooled testing ranged from 71.7% to 82.6%, and NPA ranged from 98.4% to 100.0% (Table 4). The 14 pools containing positive first-time diagnostic samples had higher PPAs than the 28 pools containing positive follow-up test samples in an LDT (Appendix Table 3).
There were 16 total pools for which >1 method showed false-negative results. Except for the 1 pool containing 4 positive specimens, which was not detected by Panther Aptima using the manufacturer’s cutoff value (Panther Aptima-M), the remaining 15 false-negative pools each contained only 1 positive specimen. For all missed pools, the Ct value of the individual positive sample was >34 (median 36.6, interquartile range 35.5–37.7) (Figure 1). Among individual positive specimens in the dataset for pools of 8, a total of 22 (37.9%) had Ct values >34. A total of 13/22 (59.1%) were false negative for the LDT, 11/22 (50.0%) for the LDT Panther Fusion, 15/22 (68%) for the LDT Panther Aptima-M, and 8/22 (36.4%)for the LDT Panther Aptima-350. Each of these false-negative samples was collected from known symptomatic or convalescent-phase patients being monitored for viral clearance; none of these samples were initial diagnostic specimens. The pooled LDT RNase P internal control Ct values were similar in false-negative (mean 23.5, 95% CI 22.7–24.3) and true-negative (mean 23.4, 95% CI 22.7–24.1; p = 0.7) pools.
Linearity Studies for Pools of 8
Figure 2

Figure 2. Performance of nucleic acid amplification tests for detection of severe acute respiratory syndrome coronavirus 2 in prospectively pooled specimens. Passing-Bablok regression and Bland-Altman plots for pools of 8 containing only...
For pools containing only 1 positive sample, the pooled rRT-PCRs showed positive systematic bias when compared with the individual LDT assay, as shown by the Passing-Bablok regression intercept value being >0. Mean bias between pooled and individual Ct values was 3.4 cycles (95% limits of agreement 1.2–5.6; p<0.001) by LDT and 4.0 cycles (95% limits of agreement 0.0–8.0; p<0.001) by Panther Fusion (Figure 2). Panther Fusion showed negative proportional bias when compared with individual and pooled LDTs, as shown by Passing-Bablok regression slopes with 95% CIs that do not contain 1. This result is additionally highlighted in the Bland-Altman plots, which demonstrate that at higher Ct values, Panther Fusion outperforms the LDT.
Model Estimates
The modeled PPA estimate is sensitive to the input parameters of proportion of positive tests, assay analytical sensitivity, and viral load distribution. The analytical sensitivity of the assay is approximated in this model by the Ct value corresponding to the probability of detecting 95% of true-positive samples, otherwise known as the 95% LoD. Specimens with Ct beyond the LoD are assigned a decreasing probability of detection on the basis of a probit regression curve, the shape of which was determined in the initial validation of the LDT (Appendix Figure 5). The viral load distribution of the tested population is approximated in this model by the proportion of samples with Ct greater than the LoD. This makes the model output independent of the actual LoD Ct value itself, enabling the model to be used across different rRT-PCRs.
Figure 3
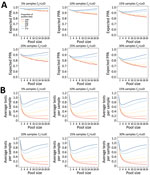
Figure 3. Performance of nucleic acid amplification tests for detection of severe acute respiratory syndrome coronavirus 2 in prospectively pooled specimens. Model-estimated PPA and testing efficiency, by pool size, proportion of tests...
Figure 4

Figure 4. Performance of nucleic acid amplification tests for detection of severe acute respiratory syndrome coronavirus 2 in prospectively pooled specimens. Model-estimated PPA and testing efficiency, by pool size, proportion of tests...
If the assay analytical sensitivity is kept constant, but the tested population changes such that a greater proportion have a Ct value beyond the 95% LoD, PPA decreases (Figure 3, panel A). Conversely, if the patient population is kept constant, but assay analytical sensitivity increases (i.e., from lower Ct LoD to higher Ct LoD), PPA increases (Figure 4, panel A). However, if assay analytical sensitivity changes and the tested population shifts accordingly such that it retains the same proportion Ct >LoD, then the PPA stays constant (Appendix Figure 6). In contrast, the average expected tests per sample is almost entirely determined by pool size and prevalence, whereas analytical sensitivity (LoD Ct) and the underlying Ct distribution minimally affect efficiency because of small absolute numbers of false-positive pools (Figure 3, panel B; Figure 4, panel B). To achieve a 5% absolute difference in efficiency with an increase in LoD Ct from 32 to 40, a prevalence of 25% would be required.
Both PPA and tests per sample are highly dependent on pool size and prevalence of infection. As prevalence increases, PPA can counterintuitively increase with larger pool sizes because there is a greater likelihood of having more than 1 positive sample in a given pool, which would be expected to increase PPA. Similarly, test efficiency can decrease with larger pool sizes because the likelihood of deconvoluting a positive pool increases. Estimated PPA and average tests per sample for inputs of percentage of positive tests 0.1%–15.0% and proportion of samples with Ct value above the LoD ranging from 5% to 30% are available (Appendix Table 4).
Model Sensitivity Analyses and Validation
Figure 5

Figure 5. Performance of nucleic acid amplification tests for detection of severe acute respiratory syndrome coronavirus 2 in prospectively pooled specimens. Empiric and modeled estimates of positive percent agreement (PPA) with 95%...
One-way deterministic and probabilistic sensitivity analyses incorporating uncertainty in the underlying model assumptions of dilutional effect and probit regression shape demonstrate a moderate (±2% to ±7%) effect on PPA, which is more pronounced with larger pool sizes and proportion of Ct values above the LoD (Appendix Figure 7). In contrast, these parameters have a much smaller effect on testing efficiency (Appendix Figure 8). The 95% CIs for the empirically determined and modeled PPAs overlapped for most of the evaluated empiric datasets, although these values overestimated PPA for the LDT follow-up tests only subset (Figure 5). For the in silico validation data, the modeled PPA was similar for pool sizes of 5 and 3, despite in silico data analysis predicting a higher PPA for pools of 3. Modeled testing efficiency was actually slightly higher for pools of 3 than pools of 5, which was probably caused by the high prevalence of 19.1% in this dataset (Appendix Table 3).
In this study, >1,600 samples were tested in pool sizes of 8 and 4 by using 3 different SARS-CoV-2 platforms, and pooled testing showed decreased PPA relative to individual samples. False-negative results occurred exclusively in pools containing samples with low estimated viral load (Ct >34). Overlapping CIS in PPA and NPA at each pool size suggest that the lower test performance is inherent to the pooling process itself, rather than the assay. Although Panther Fusion Ct values were on average higher than those of the LDT, the negative proportional bias suggests that at low estimated viral loads (Ct >36), the Panther Fusion outperformed the LDT. This finding might be caused by the different targets of amplification (envelope gene versus open reading frame 1ab) or PCR efficiency. These subtle differences between the 2 assays highlight the method-dependent nature of test performance, a variable that cannot be anticipated, and therefore is not explicitly accounted for in most statistical models of pooled testing. Thus, method comparison studies should be performed before large-scale implementation of any pooled testing strategies, especially those that use different platforms for the pooled and individual stages of testing.
The findings of our study contrast with those of a recent study, which concluded that pooling in groups of 8 did not compromise test performance (5). This finding might be explained by differences in patient population, higher proportion of positive pools and rRT-PCR result interpretation. Another recent study of artificially constructed pools reported no major decrease in sensitivity in pools of <32 samples (3). This finding is probably explained by the relatively low starting Ct values of individual positive samples in this study; none exceeded a Ct of 30. However, this study and other experimental studies have shown empirical increases in pooled Ct values directly proportional to dilution factor, a relationship that was also observed in our study (3,4,9).
These differences highlight the effect of viral load distribution and assay analytical sensitivity on pooled test performance, both of which should be taken into account when choosing pool size and diagnostic assay. Although samples with Ct values >33 have not been reported to produce cultivable virus in convalescent phase COVID-19 patients (21), >15% of first-time diagnostic specimens in our laboratory were detected at a Ct >35. A similar proportion of weakly positive samples that had high Ct values at a public health department virology laboratory in New York has been described (S.B. Griesemer, unpub. data). Assays with lower analytical sensitivity may miss specimens with late Ct values, for which the potential associated burden of onward transmission is currently unclear.
The stochastic model in this study demonstrated that expected PPA between pooled and individual rRT-PCRs was highly dependent on assay analytical sensitivity (represented by 95% LoD), viral load distribution of test-positive patients (represented by proportion Ct >LoD), pool size, and disease prevalence (represented by proportion of tests positive). The model outputs were not always intuitive; larger pool sizes were not always less sensitive or more efficient. With increased prevalence, larger pool sizes were more sensitive because they were more likely to contain >1 positive sample/pool. They were also less efficient because a larger proportion were positive and required deconvolution.
The model output was largely independent of the actual LoD and viral load-to-Ct value relationship of a given assay, making it generalizable across different rRT-PCRs. The only input parameters it requires are the proportion of positive test results and the proportion of samples with Ct >LoD, both of which should be readily available to any laboratories conducting clinical testing. Future studies on the sensitivity of pooled testing strategies should report these parameters.
Previous models of pooled testing strategies for SARS-CoV-2 have primarily examined the effect of pool size and prevalence on testing efficiency but have not addressed the expected decrement in assay sensitivity that accompanies a putative increase in efficiency (6,22). Those studies that have examined sensitivity did not explicitly model the effect of variable viral load distribution of test-positive patients, a parameter that can vary based on the underlying patient population (asymptomatic versus symptomatic and severe versus nonsevere), purpose of testing (diagnostic versus follow-up), and specimen type (8,23–27). In addition, previous modeling studies and in silico analyses have mostly used the Ct cutoff value of the assay, assuming 100% detection below the cutoff value, and 0% detection above it. In contrast, our model incorporates the probabilistic nature of detection at and above the LoD, which better approximates reality.
Our approach is limited by the generalizability of the probit regression shape and the equation estimating dilutional effect, as demonstrated by the variability seen on probabilistic and deterministic sensitivity analysis. Furthermore, the model assumes that the PCR is 100% efficient and that it is devoid of any proportional bias between individual and pooled tests. In addition, the model might underestimate PPA and efficiency of pooled testing if samples in each pool are not independent; placing samples with higher pretest probability in the same pool would decrease the total number of positive pools and increase the likelihood of detection. This feature could be leveraged by pooling specimens from persons in the same household or social distancing pod, such as coworkers on the same shift or students sharing a classroom. These factors, among others, might be the reasons for which the probabilistic sensitivity analysis CIs often did not contain the empiric point estimate in our validation data. These unaccounted-for factors might limit the ability of the model to provide a reliable point estimate.
The strengths of our study include its relatively large sample size, prospective rather than experimental construction of pools, and assessment of 2 different pool sizes. It also compared 3 different SARS-CoV-2 assays, 2 of which are commercially available on highly automated platforms suitable for large-scale testing. Our study was limited by its assessment of only a 2-stage pooling strategy. An additional limitation includes selection bias because the proportion of positive test results in the study specimens was higher because of the inclusion of follow-up samples from known COVID-19 patients enrolled in clinical research studies. Finally, test performance might vary depending on specimen collection medium, which we did not assess in this study (S.B. Griesemer, unpub. data).
In conclusion, a 2-stage pooled testing strategy for detection of SARS-CoV-2 by nucleic acid amplification is feasible and has the potential to strongly increase testing capacity. However, increased pool size and efficiency can compromise PPA. More studies examining early viral load kinetics and infectiousness are needed to fully evaluate the risks versus benefits of pooled testing. We provide a model to predict optimal pool size and associated expected PPA based on limit of detection, Ct value distribution, and proportion of positive test results. If this model can be externally validated, it might be useful in guiding SARS-CoV-2 pooled testing in other laboratories and as part of an adaptive risk-based strategy.
Dr. Wang is a resident physician in the Department of Anatomic and Clinical Pathology at Stanford Hospital, Palo Alto, CA. Her primary research interests focus on infectious disease molecular diagnostics and the application of machine-learning algorithms and other computational methods to effectively leverage those diagnostics for patient care.
Acknowledgments
We thank the Stanford Clinical Virology Laboratory staff for their dedication and commitment to patient care in the face of unprecedented challenges presented by the COVID-19 pandemic, and Hologic, Inc. for graciously providing in silico data from their pooling evaluations.
N.S.-A. is supported by a Stanford Graduate Fellowship.
Work was performed by B.H. during his personal time. B.H. is an employee of Google LLC.
References
- Hogan CA, Sahoo MK, Pinsky BA. Sample pooling as a strategy to detect community transmission of SARS-CoV-2. JAMA. 2020;323:1967–9. DOIPubMedGoogle Scholar
- Wacharapluesadee S, Kaewpom T, Ampoot W, Ghai S, Khamhang W, Worachotsueptrakun K, et al. Evaluating the efficiency of specimen pooling for PCR-based detection of COVID-19. J Med Virol. 2020;92:2193–9. DOIPubMedGoogle Scholar
- Yelin I, Aharony N, Shaer Tamar E, Argoetti A, Messer E, Berenbaum D, et al. Evaluation of COVID-19 RT-qPCR test in multi-sample pools. Clin Infect Dis. 2020;May 2:ciaa531.
- Abdalhamid B, Bilder CR, McCutchen EL, Hinrichs SH, Koepsell SA, Iwen PC. Assessment of specimen pooling to conserve SARS CoV-2 testing resources. Am J Clin Pathol. 2020;153:715–8. DOIPubMedGoogle Scholar
- Ben-Ami R, Klochendler A, Seidel M, Sido T, Gurel-Gurevich O, Yassour M, et al.; Hebrew University-Hadassah COVID-19 Diagnosis Team. Large-scale implementation of pooled RNA extraction and RT-PCR for SARS-CoV-2 detection. Clin Microbiol Infect. 2020;26:1248–53. DOIPubMedGoogle Scholar
- Eberhardt JN, Breuckmann NP, Eberhardt CS. Multi-stage group testing improves efficiency of large-scale COVID-19 screening. J Clin Virol. 2020;128:
104382 . DOIPubMedGoogle Scholar - Lohse S, Pfuhl T, Berkó-Göttel B, Rissland J, Geißler T, Gärtner B, et al. Pooling of samples for testing for SARS-CoV-2 in asymptomatic people. Lancet Infect Dis. 2020;20:1231–2. DOIPubMedGoogle Scholar
- Pilcher CD, Westreich D, Hudgens MG. Group testing for SARS-CoV-2 to enable rapid scale-up of testing and real-time surveillance of incidence. J Infect Dis. 2020;222:903–9. DOIPubMedGoogle Scholar
- Eis-Hübinger AM, Hönemann M, Wenzel JJ, Berger A, Widera M, Schmidt B, et al. Ad hoc laboratory-based surveillance of SARS-CoV-2 by real-time RT-PCR using minipools of RNA prepared from routine respiratory samples. J Clin Virol. 2020;127:
104381 . DOIPubMedGoogle Scholar - Perchetti GA, Sullivan K-W, Pepper G, Huang M-L, Breit N, Mathias P, et al. Pooling of SARS-CoV-2 samples to increase molecular testing throughput. J Clin Virol. 2020;131:
104570 . DOIPubMedGoogle Scholar - Busch MP, Kleinman SH, Jackson B, Stramer SL, Hewlett I, Preston S. Committee report. Nucleic acid amplification testing of blood donors for transfusion-transmitted infectious diseases: Report of the Interorganizational Task Force on Nucleic Acid Amplification Testing of Blood Donors. Transfusion. 2000;40:143–59. DOIPubMedGoogle Scholar
- Custer B, Tomasulo PA, Murphy EL, Caglioti S, Harpool D, McEvoy P, et al. Triggers for switching from minipool testing by nucleic acid technology to individual-donation nucleic acid testing for West Nile virus: analysis of 2003 data to inform 2004 decision making. Transfusion. 2004;44:1547–54. DOIPubMedGoogle Scholar
- Food and Drug Administration. Molecular diagnostic template for laboratories, July 28, 2020 [cited 2020 Sep 18]. https://www.fda.gov/media/135658/download
- Food and Drug Administration. EUA summary: SARS-CoV-2 RT-PCR assay (Stanford Health Care Clinical Virology Laboratory). April 8, 2020 [cited 2020 Jul 11]. https://www.fda.gov/media/136818/download
- Bulterys PL, Garamani N, Stevens B, Sahoo MK, Huang C, Hogan CA, et al. Comparison of a laboratory-developed test targeting the envelope gene with three nucleic acid amplification tests for detection of SARS-CoV-2. J Clin Virol. 2020;129:
104427 . DOIPubMedGoogle Scholar - Corman VM, Landt O, Kaiser M, Molenkamp R, Meijer A, Chu DKW, et al. Detection of 2019 novel coronavirus (2019-nCoV) by real-time RT-PCR. Euro Surveill. 2020;25:1–8. DOIPubMedGoogle Scholar
- Food and Drug Administration. EUA summary: SARS-CoV-2 assay (Panther Fusion System), April 24, 2020 [cited 2020 Jul 11]. https://www.fda.gov/media/136156/download
- Food and Drug Administration. EUA Summary: Aptima SARS-CoV-2, May 14, 2020 [cited 2020 Jul 11]. https://www.fda.gov/media/138096/download
- Robin X, Turck N, Hainard A, Tiberti N, Lisacek F, Sanchez JC, et al. pROC: an open-source package for R and S+ to analyze and compare ROC curves. BMC Bioinformatics. 2011;12:77. DOIPubMedGoogle Scholar
- Altman D, Machin D, Bryant T, Gardner M, editors. Statistics with confidence. 2nd ed. London: British Medical Journal Books; 2000.
- La Scola B, Le Bideau M, Andreani J, Hoang VT, Grimaldier C, Colson P, et al. Viral RNA load as determined by cell culture as a management tool for discharge of SARS-CoV-2 patients from infectious disease wards. Eur J Clin Microbiol Infect Dis. 2020;39:1059–61. DOIPubMedGoogle Scholar
- Aragón-Caqueo D, Fernández-Salinas J, Laroze D. Optimization of group size in pool testing strategy for SARS-CoV-2: A simple mathematical model. J Med Virol. 2020;92:1988–94. DOIPubMedGoogle Scholar
- Cherif A, Grobe N, Wang X, Kotanko P. Simulation of pool testing to identify patients with coronavirus disease 2019 under conditions of limited test availability. JAMA Netw Open. 2020;3:
e2013075 . DOIPubMedGoogle Scholar - Pan Y, Zhang D, Yang P, Poon LLM, Wang Q. Viral load of SARS-CoV-2 in clinical samples. Lancet Infect Dis. 2020;20:411–2. DOIPubMedGoogle Scholar
- Xu T, Chen C, Zhu Z, Cui M, Chen C, Dai H, et al. Clinical features and dynamics of viral load in imported and non-imported patients with COVID-19. Int J Infect Dis. 2020;94:68–71. DOIPubMedGoogle Scholar
- To KK, Tsang OT, Leung WS, Tam AR, Wu TC, Lung DC, et al. Temporal profiles of viral load in posterior oropharyngeal saliva samples and serum antibody responses during infection by SARS-CoV-2: an observational cohort study. Lancet Infect Dis. 2020;20:565–74. DOIPubMedGoogle Scholar
- Wölfel R, Corman VM, Guggemos W, Seilmaier M, Zange S, Müller MA, et al. Virological assessment of hospitalized patients with COVID-2019. Nature. 2020;581:465–9. DOIPubMedGoogle Scholar
Figures
Tables
Cite This ArticleOriginal Publication Date: November 12, 2020
Table of Contents – Volume 27, Number 1—January 2021
| EID Search Options |
|---|
|
|
|
|
|
|
Please use the form below to submit correspondence to the authors or contact them at the following address:
Benjamin A. Pinsky, Stanford University School of Medicine, 3375 Hillview, Rm 2913, Palo Alto, CA 94304, USA
Top